


Brain caps on…this was a fun one. There are a few ways to follow an RSS feed for a Mastodon instance if you’re looking to follow a single user. But…what about showing the whole public feed? That’s a different story…there’s no built-in method to show the entire public feed of the server. So…we’ll make a feed.
What we’re looking to do here is take the whole public feed for the instance and feed it out to a something the site can display. This took some trial and error but with what I’ve learned over the last few years and the help of ChatGPT I’ve patched together some code that makes it all happen. Here’s what we’ve got to do:
- Write out a Python script that pulls the public feed from the Mastodon instance and places it into a file that can be read by the RSS service.
- Add a system cron job to run that script at a pre-determined frequency to update that file.
- Add the RSS feed to the site using either the built-in RSS feed widget, or use a 3rd party service to add it in.
Write the script
We’re going to use Python for this. I’m going to be accessing the server instance using an API key, so it doesn’t matter where you save the script (on the machine running the Mastodon instance or on another machine). Since most of my automated scripts run on the web server, it’ll get saved there. Using notepad++, or the built-in editor in Linux, create a new Python script with the name something.py. Here’s the contents of that file:
import requests
import xml.etree.ElementTree as ET
from xml.dom import minidom
def prettify_xml(elem):
rough_string = ET.tostring(elem, 'utf-8')
reparsed = minidom.parseString(rough_string)
return reparsed.toprettyxml(indent=" ")
# Replace this instance url with your actual mastodon instance url
instance_url = "https://mymastodoninstance"
public_timeline_url = f"{instance_url}/api/v1/timelines/public"
# Replace these with your actual client credentials and access token
client_id = "xxxx"
client_secret = "xxxx"
access_token = "xxxx"
# Add cache control headers
headers = {
"Cache-Control": "no-cache, no-store, must-revalidate",
"Pragma": "no-cache",
"Expires": "0"
}
# Obtain data using authentication
response = requests.get(public_timeline_url, headers={"Authorization": f"Bearer {access_token}"})
data = response.json()
# Check for errors in the API response
if 'error' in data:
print("Error:", data['error'])
exit()
# Create the root element with the Atom namespace
rss = ET.Element("{http://www.w3.org/2005/Atom}rss")
rss.set("version", "2.0")
# Declare the media namespace
media_namespace = "http://search.yahoo.com/mrss/"
media_prefix = "media"
ET.register_namespace(media_prefix, media_namespace)
channel = ET.SubElement(rss, "channel")
title = ET.SubElement(channel, "title")
title.text = "Schleicher Social Timeline"
link = ET.SubElement(channel, "link")
link.text = public_timeline_url
description = ET.SubElement(channel, "description")
description.text = "Schleicher Social RSS Feed"
# Process the data and generate RSS feed
for item in data:
rss_item = ET.SubElement(channel, "item")
item_title = ET.SubElement(rss_item, "title")
item_title.text = f"New Schleicher Social post by {item['account']['display_name']}"
item_link = ET.SubElement(rss_item, "link")
item_link.text = item['url']
item_description = ET.SubElement(rss_item, "description")
item_description.text = item['content']
item_author = ET.SubElement(rss_item, "author")
item_author.text = item['account']['display_name']
item_pub_date = ET.SubElement(rss_item, "pubDate")
item_pub_date.text = item['created_at']
# Add media attachments to the description and media content in <media:content> format
if 'media_attachments' in item:
for media in item['media_attachments']:
if media['type'] == 'image':
# Add image as a separate <media:content> tag
media_content = ET.Element(f"{{{media_namespace}}}content")
media_content.set("height", "151")
media_content.set("medium", "image")
media_content.set("url", media['url'])
media_content.set("width", "151")
# Append image tag to the description
img_tag = f"<img src='{media['url']}' alt='Image'>"
item_description.text += f"<br>{img_tag}"
rss_item.append(media_content)
# Replace with your file location for the rss feed
with open('/some/file/path/mastodon_rss.xml', 'w') as f:
f.write(prettify_xml(rss))Importantly, this script is tailored to the requirements of Elfsight (the third party service I use to display the feed). It will most likely work with any third party service, and works just fine with the RSS feed widget. That being said, if you run into display issues, you may need to check the technical documents of the third party platform you are using for specific formatting syntax for their widget.
You need to replace some of the script with your info:
- Replace the Mastodon instance URL with your server address
- Replace the login credentials with your API (see the next section on creating those)
- Replace the file path with the location you want to save the generated file
I recommend saving the generated file in the root directory of the website you want to display the feed on (i.e., /var/www/html/yourdomain/mastodon_rss.xml).
Access Tokens and the API
An important part of this is the access to your server instance. To allow access to the feed you need to create an application-specific API key. I did this under the bot account, but you also need admin-level or greater rights. Add an application by going to your settings and then hit the Development link. Next, add a new application. Fill out all required info, the redirect URI does not matter, and for scope you only need to check “Read” and “read:lists”.
Now, in the script you just created, find the client credentials section and replace “xxxx” with the appropriate values from the newly created Mastodon API.
Script Results
If you’ve done everything right, at this point running the script from the command line would generate an XML file. Opening this file, or typing the address to the file in a browser bar, would show a raw feed page:
<ns0:rss version="2.0">
<channel>
<title>Schleicher Social Timeline</title>
<link>https://schleicher.social/api/v1/timelines/public</link>
<description>Schleicher Social RSS Feed</description>
<item>
<title>New Schleicher Social post by The Schleicher Bot</title>
<link>
https://schleicher.social/@Schleicher/112634593332895774
</link>
<description>
<p>6/17/24</p><p>Happy National Apple Strudel Day! Happy Birthday: Kenlee June 19/ Brandon June 22 / Kyle June 25 Prayer: Dennis and family as they mourn the passing of his mother Greetings from NC…finally got a little rain last night…hope it was enough for the corn … History lesson about Roller Skating….especially for those of us who grew up at the Mission Roller Rink. It was the most popular sport in the 1950</p><p><a href="https://family.schleicher.social/6-17-24/" target="_blank" rel="nofollow noopener noreferrer" translate="no"><span class="invisible">https://</span><span class="ellipsis">family.schleicher.social/6-17-</span><span class="invisible">24/</span></a></p><p><a href="https://schleicher.social/tags/BoarReport" class="mention hashtag" rel="tag">#<span>BoarReport</span></a> #2024 <a href="https://schleicher.social/tags/BoarReport" class="mention hashtag" rel="tag">#<span>BoarReport</span></a></p><br><img src='https://schleicher.social/system/media_attachments/files/112/634/593/308/581/083/original/e446e7e5d80f1bbb.jpg' alt='Image'>
</description>
<author>The Schleicher Bot</author>
<pubDate>2024-06-17T23:38:20.812Z</pubDate>
<media:content height="151" medium="image" url="https://schleicher.social/system/media_attachments/files/112/634/593/308/581/083/original/e446e7e5d80f1bbb.jpg" width="151"/>
</item>
<item>
<title>New Schleicher Social post by The Schleicher Bot</title>
<link>
https://schleicher.social/@Schleicher/112609140712769778
</link>
<description>
<p>Good morning! We've got a birthday today! Have a GREAT day Nick May 🎉 !</p>
</description>
<author>The Schleicher Bot</author>
<pubDate>2024-06-13T11:45:24.646Z</pubDate>
</item>
System Cron Jobs
Next up is a cron job. You want to regenerate the XML file so that new posts are caught, rather than just serving up a static file. I won’t go into the specifics of setting up the cron job since depending on the platform you’re using it can be widely different. I use Webmin so setting up new cron jobs is click and go; in this case I set up a cron job to run the python script every 15 minutes to catch and regenerate the XML file with any new posts.
Display the Feed
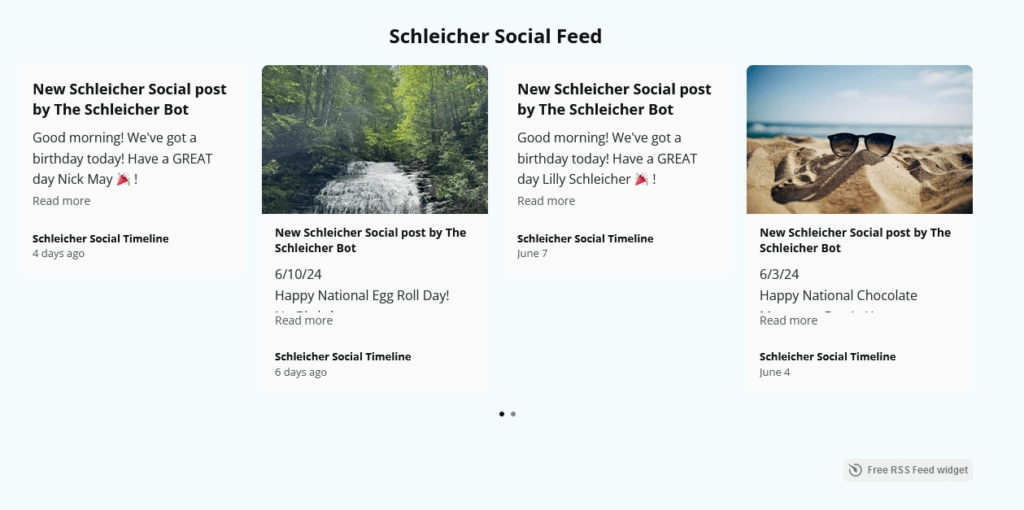
Last up, use a service to display the feed, or use a built-in widget to display post updates. I use ElfSight to display the feed; its free and it has a decent appearance. Others include Sociable Kit, but for updates to the feed you have to manually request updates without a paid plan.
Again, specific steps depend on the service, but in a nutshell you will usually just upload the public URL of the RSS feed (that’s why we save the file to the root directory of the website), pick the appearance, and then embed either the HTML code or use a widget to display the feed.
Author: Zack
Pharmacist, tech guy, gamer, fixer. Good at a little bit of everything.